D4Explainer: In-Distribution GNN Explanations via Discrete Denoising Diffusion
Introduction
Graph neural networks (GNNs) have rapidly gained popularity recently due to their ability to model relational data. However, when it comes to critical decision-making and high-stake applications, such as healthcare, finance, and autonomous systems, the explainability of GNNs is fundamental for humans to understand the model’s decision-making logic and build trust in the deployment of GNNs in real-world scenarios.
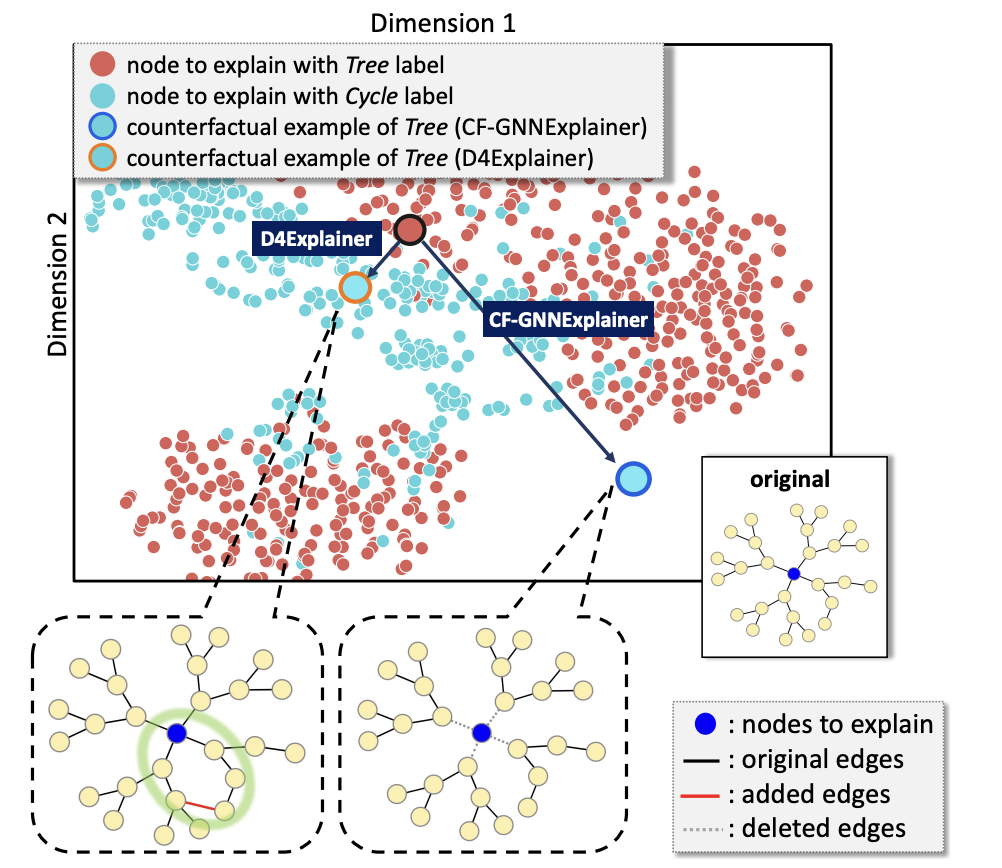 Figure 1: t-SNE Projection of Tree-Cycle dataset,where Cycle is a counterfactual motif for Tree.
Figure 1: t-SNE Projection of Tree-Cycle dataset,where Cycle is a counterfactual motif for Tree.
However, existing methods often rely on out-of-distribution (OOD) effects to generate counterfactual explanations, neglecting the in-distribution properties that are critical for producing reliable explanations. Figure 1 shows the t-SNE projection of the Tree-Cycle dataset, where graphs are labeled as Tree or Cycle based on whether they present the corresponding structures. Specifically, CF-GNNExplainer generates counterfactual explanations for a node with Tree label by removing its neighbor edges. While the explanation doesn't maintain any discriminative information on the Cycle class, it could still be predicted as Cycle with high probability due to the OOD effect, making the explanation unreliable. Additionally, current explainers struggle to handle multiple explanation scenarios, such as instance-level and model-level explanations.
Leveraging graph diffusion models, which effectively capture complex distributions on graphs, offers a promising direction to address these limitations and enhance the robustness and versatility of GNN explainability methods. In this work, we propose D4Explainer based on graph diffusion models, a novel approach to generate in-distribution, diverse and robust explanations. Moreover, D4Explainer is the first framework to unify both counterfactual and model-level explanation scenarios.
Method
D4Explainer is designed for two distinct explanation scenarios: counterfactual explanation and model-level explanation. In counterfactual explanation, D4Explainer employs a Forward diffusion process to create a sequence of noisy versions and trains a Denoising model to effectively capture the desired distribution of counterfactual graphs. For model-level explanation, D4Explainer trains a Denoising model to recover the underlying original distribution and leverages a well-trained GNN to progressively enhance the explanation confidence during the reverse sampling. An overview is shown in Figure 2.
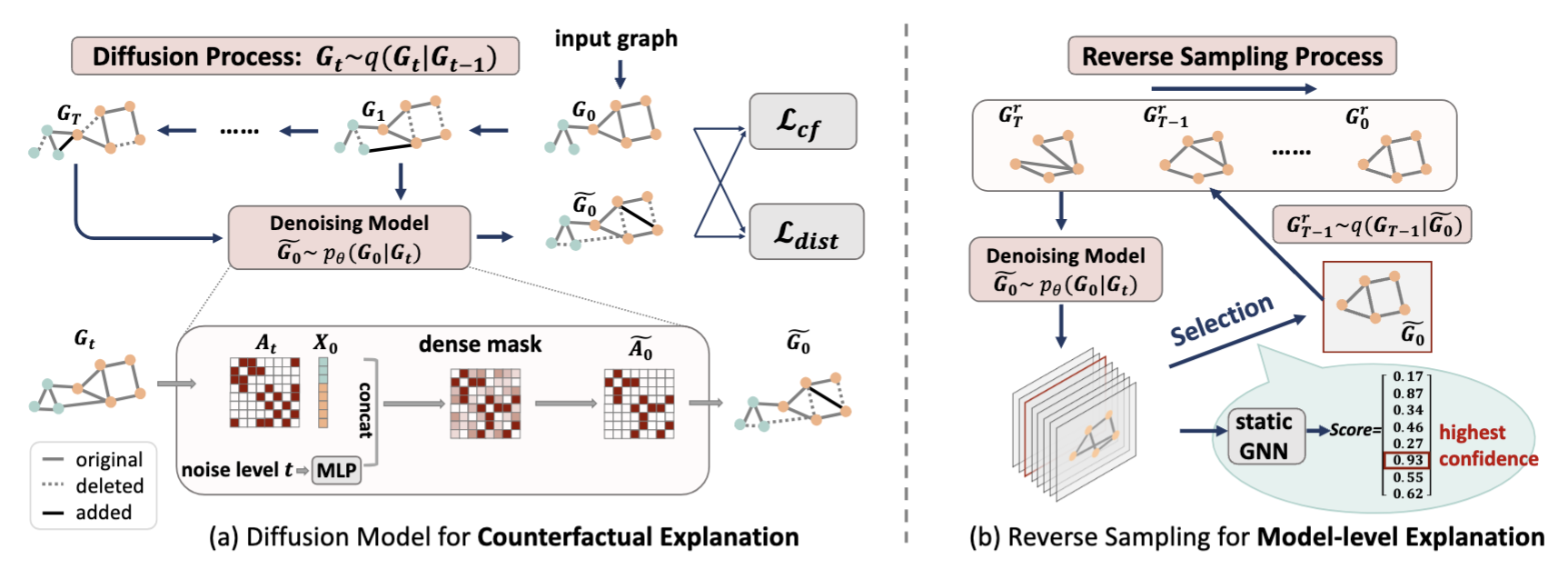 Figure 2: Overview of D4Explainer. (a) Diffusion Model for counterfactual explanations. The diffusion process q(G_t
Figure 2: Overview of D4Explainer. (a) Diffusion Model for counterfactual explanations. The diffusion process q(G_t
Counterfactual Explanation Generation
Forward Diffusion Process
Let denote the timestep of the diffusion process, which is also a noise level indicator. Let denote the one-hot version of the adjacency matrix at timestep , where each element is a 2-dimensional one-hot encoding of the presence or absence of the -th element in the adjacency matrix. The forward diffusion process is a Markov chain with a transition matrix , that progressively transforms the input graph into pure noise. Mathematically, the forward diffusion process can be written as where is a categorical distribution over the one-hot vector with probability vector . The multi-step diffusion has a closed form as , where .
Denoising Model
The Denoising Model takes as input the noisy adjacency matrix corresponding to a noisy graph , the node features of the original graph , noise level indicator , and then predicts the dense adjacency matrix. The Denoising Model is set as an extension of the Provably Powerful Graph Network (PGNN).
Loss Function
Counterfactual explanations necessitate both counterfactual property and proximity to the original graph. The overall training objective includes two parts: and . The distribution loss is equivalent to the cross-entropy loss between and over the full adjacency matrix, which guarantees the proximity of generated counterfactual explanations to the original graph. To optimize the counterfactual property, is defined as where is the well-trained GNN classifier, denotes the probability for the original label predicted by , given the generated graph . The overall loss is , where is a hyper-parameter that balances the counterfactual and in-distribution properties.
Model-level Explanation Generation
The goal of model-level explanation is to generate class-wise graph pattern. Let denote the target class. Each reverse sampling step can be formulated as a conditional generation satisfying the following equation,
In model-level explanation scenario, a denoising model is trained with only. The reverse sampling algorithm is shown as follows.
 Algorithm
Algorithm
Specifically, we repeat the sampling steps and progressively increase the explanation confidence (i.e., ) by selecting with the highest confidences (in Step 5).
Experiments
Datasets and Baselines
We evaluate our approach on both node classification and graph classification tasks. Node Classification:
- Synthetic Datasets: BA-Shapes, Tree-Cycle, Tree-Grids, where structural motifs determine node labels. A vanilla GCN achieves over accuracy.
- Real-World Dataset: Cornell, a heterophilous webpage graph with complex relationships. EGNN, designed for heterophilous graphs, achieves accuracy.
Graph Classification:
- Synthetic Dataset: BA-3Motif with three graph classes (cycle, grid, house motifs).
- Real-World Molecule Datasets: Mutag, BBBP, and NCI1, where chemical functionalities determine graph labels. A GCN is used for BA-3Motif, BBBP, and NCI1, while GIN is used for Mutag. Baselines:
We select CF-GNNExplainer, GNNExplainer, SAExplainer, GradCam, IGExplainer, PGExplainer, PGMExplainer, CXPlain as baselines for counterfactual explanations, where factual explainers are adapted by constructing subgraphs with the least important edges.
XGNN, the state-of-the-art method for GNN model-level explanations is selected as the baseline for model-level explanations.
Counterfactual Explanation Performance
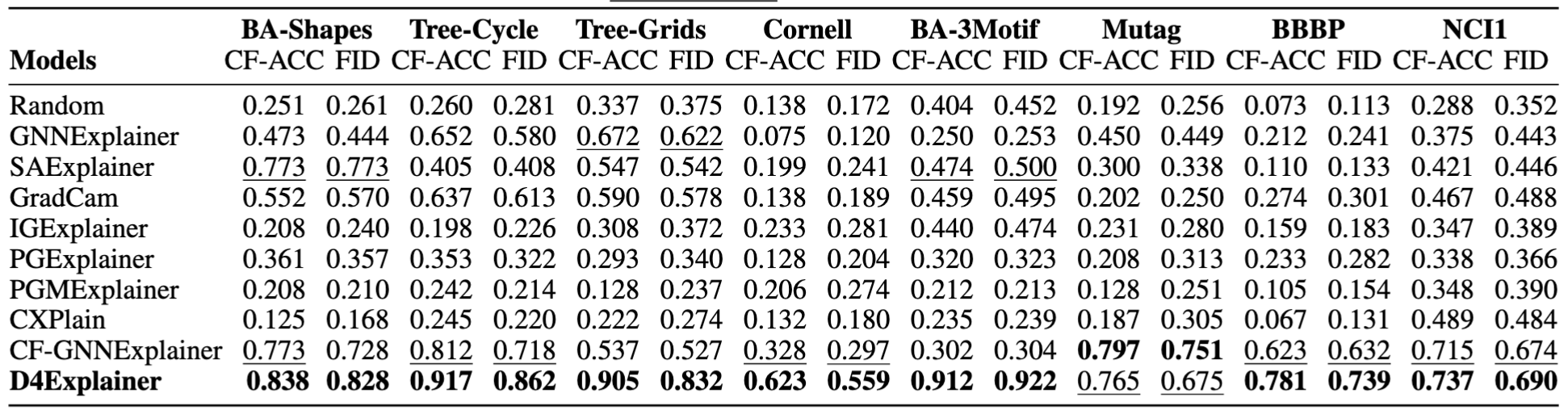 Table 1: CF-ACC AUC and Fidelity (FID) AUC of D4Explainer and baseline explainers over eight datasets. We report AUC values computed over 10 modification ratios from 0 to 0.3. The best result is in bold and the second best result is underline
Table 1: CF-ACC AUC and Fidelity (FID) AUC of D4Explainer and baseline explainers over eight datasets. We report AUC values computed over 10 modification ratios from 0 to 0.3. The best result is in bold and the second best result is underline
Counterfactual Accuracy (CF-ACC) is defined as the proportion of generated explanations that change the model’s prediction, while Fidelity (FID) measures the change in output probability over the original class. As can be seen from the table, D4Explainer achieves the best performances on seven out of eight datasets, with especially strong CF-ACC AUC values () on Tree-Cycle, Tree-Grids, and BA-3Motif. Notably, D4Explainer consistently works well on explaining both node classification and graph classification tasks, while the efficacy of baselines is unstable across datasets.
In-Distribution Evaluation
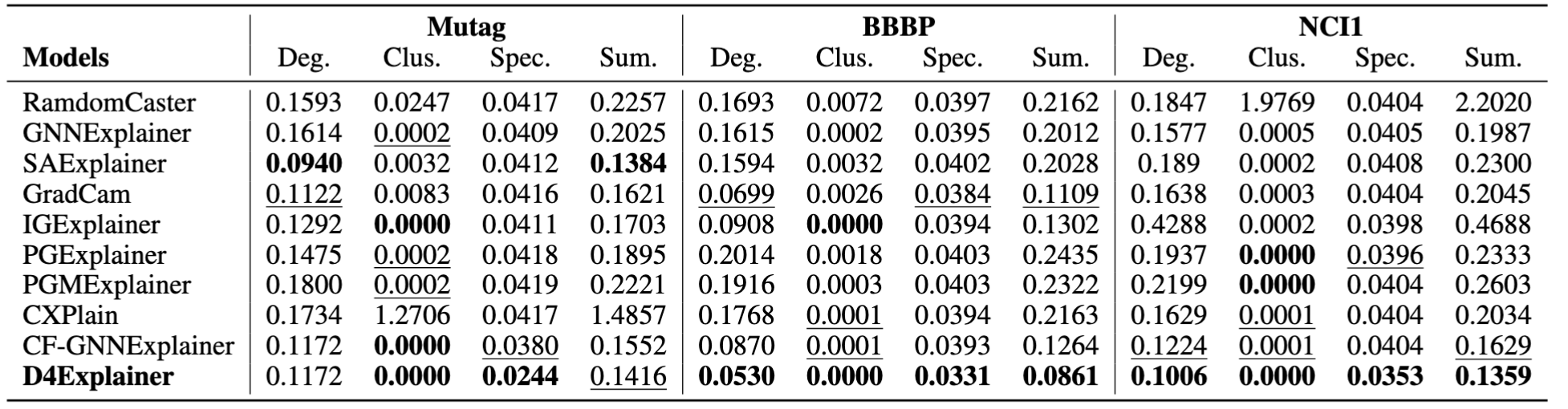 Table 2: MMD distances between the generated explanations and test graphs.
To evaluate the in-distribution property of the generated explanations, we adopt the maximum mean discrepancy (MMD) to compare distributions of graph statistics between the generated counterfactual explanations and original test graphs, as reported in Table 2. The MMD results verify the effectiveness of D4Explainer in capturing the underlying distribution of datasets and generating in-distribution and more faithful explanations.
Table 2: MMD distances between the generated explanations and test graphs.
To evaluate the in-distribution property of the generated explanations, we adopt the maximum mean discrepancy (MMD) to compare distributions of graph statistics between the generated counterfactual explanations and original test graphs, as reported in Table 2. The MMD results verify the effectiveness of D4Explainer in capturing the underlying distribution of datasets and generating in-distribution and more faithful explanations.
Explanation Diversity Evaluation
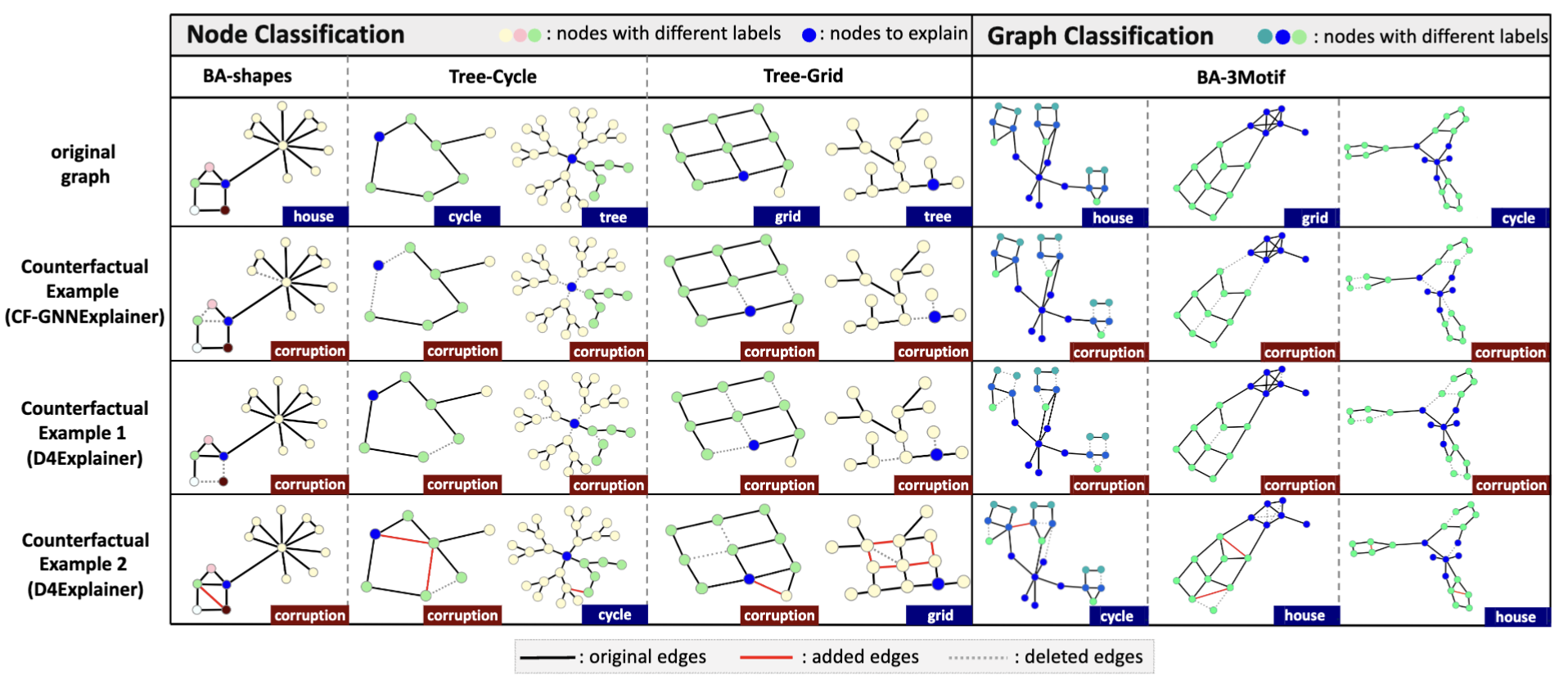 Figure 3: Counterfactual explanations comparison.
We evaluate the diversity of counterfactual explanations in Figure 3. There are two main approaches to generating counterfactual explanations.
Figure 3: Counterfactual explanations comparison.
We evaluate the diversity of counterfactual explanations in Figure 3. There are two main approaches to generating counterfactual explanations.
- The first one is deleting determinant edges and destroying the original motif, thus greatly influencing the model's prediction.
- The second one is converting the original motifs to truly counterfactual motifs through both deleting and adding essential edges.
Previous methods can only produce the first type of counterfactual explanations, while D4Explainer makes the second approach possible and successful.
Robustness Evaluation
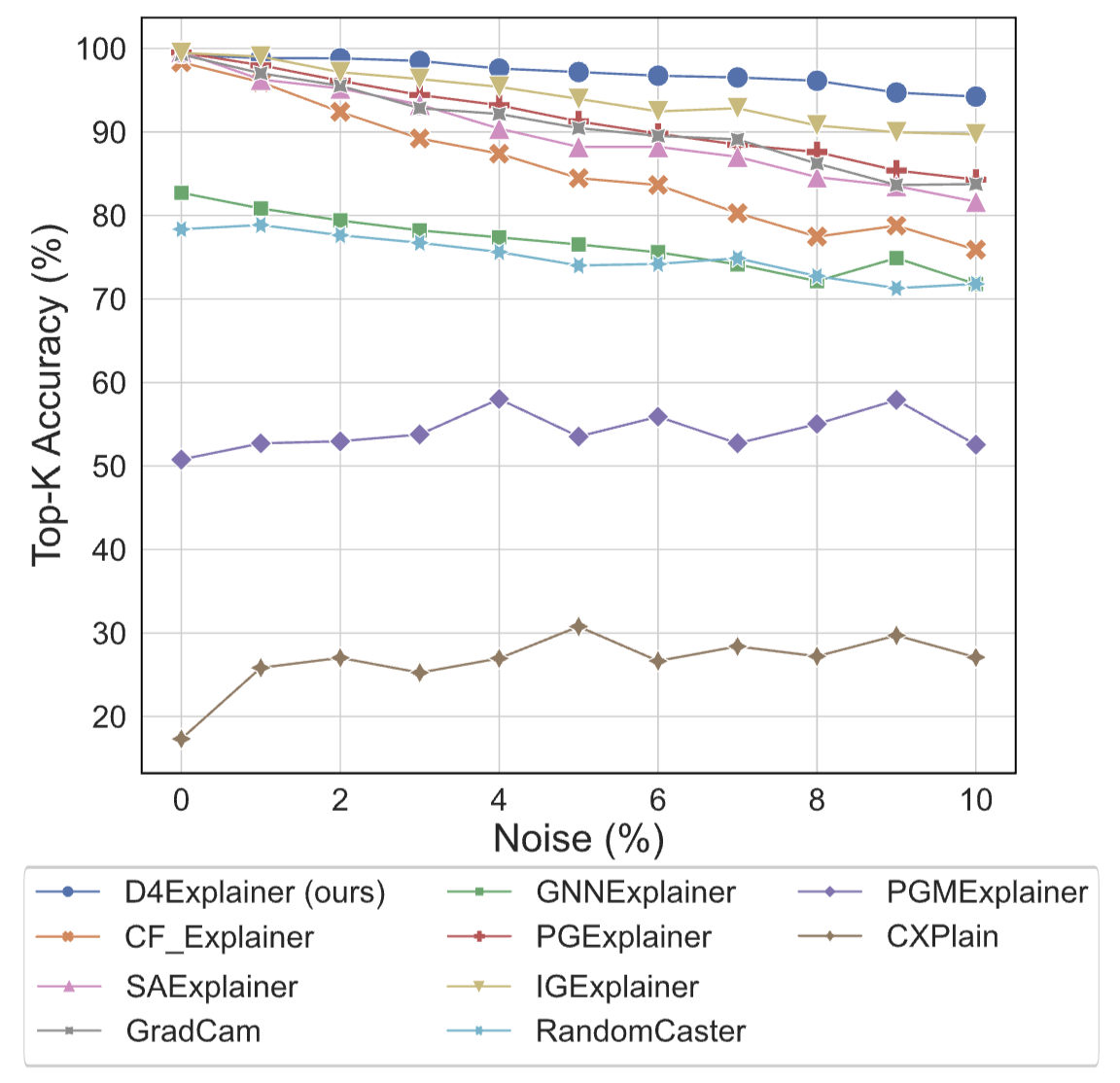 Figure 4: Top-K accuracy w.r.t. noise levels on BBBP dataset
We compare the counterfactual explanations produced on the original graph and its perturbed counterpart. A robust model would predict the same explanation for both inputs. We identify the most relevant edges in the original counterfactual explanation and compute the fraction of these edges present in the explanation of its noisy version, denoted by Top- Accuracy. Results on BBBP dataset are shown in Figure 4. We observe that D4Explainer outperforms all baselines over different noise levels from 0 to .
Figure 4: Top-K accuracy w.r.t. noise levels on BBBP dataset
We compare the counterfactual explanations produced on the original graph and its perturbed counterpart. A robust model would predict the same explanation for both inputs. We identify the most relevant edges in the original counterfactual explanation and compute the fraction of these edges present in the explanation of its noisy version, denoted by Top- Accuracy. Results on BBBP dataset are shown in Figure 4. We observe that D4Explainer outperforms all baselines over different noise levels from 0 to .
Model-level Explanation
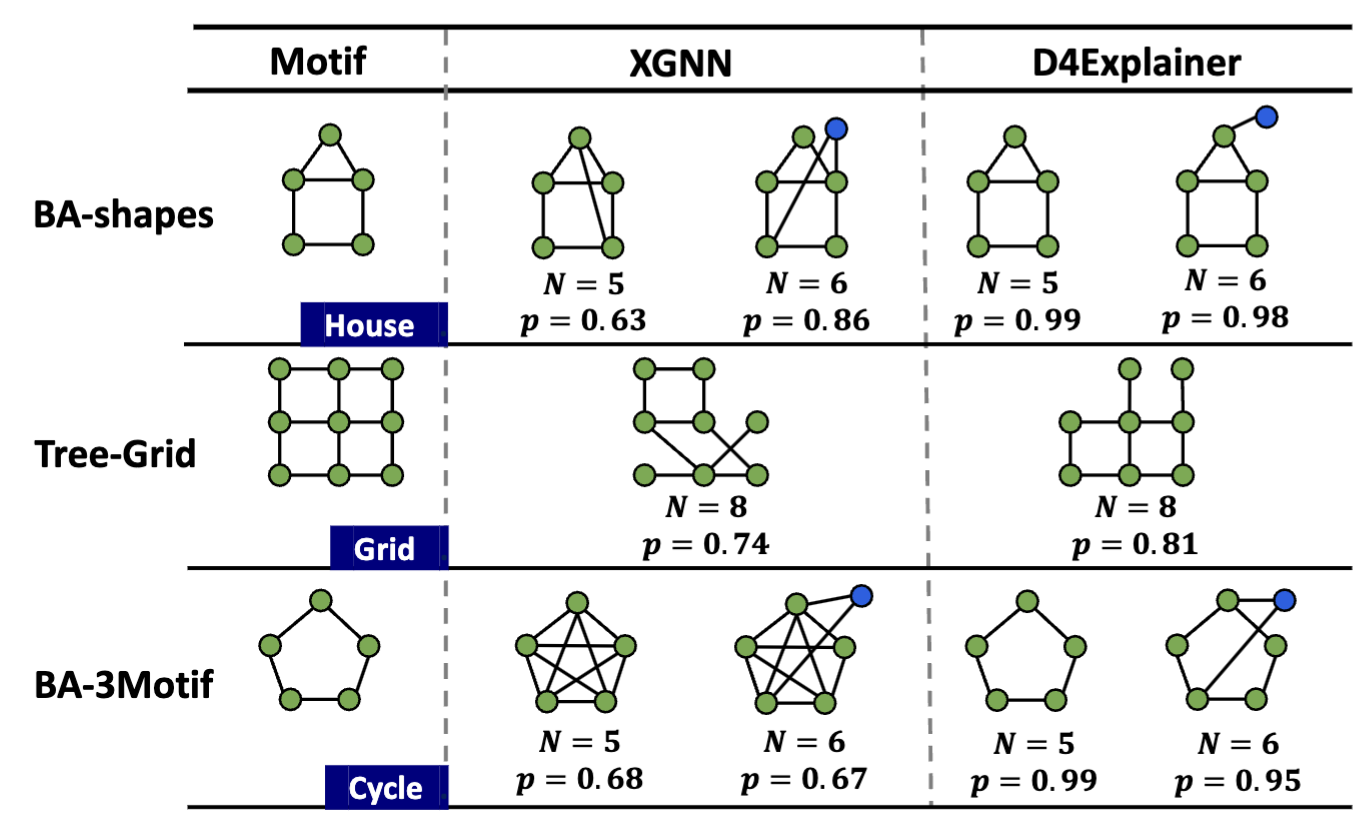 Figure 5: Qualitative evaluation of D4Explainer
We qualitatively evaluate the generated explanations with different pre-defined numbers of nodes , shown in Figure 5. We observe that D4Explainer can produce more determinant graph patterns with nearly confidence for synthetic datasets, e.g., BA-shapes and BA-3Motif.
Figure 5: Qualitative evaluation of D4Explainer
We qualitatively evaluate the generated explanations with different pre-defined numbers of nodes , shown in Figure 5. We observe that D4Explainer can produce more determinant graph patterns with nearly confidence for synthetic datasets, e.g., BA-shapes and BA-3Motif.