From Similarity to Superiority: Channel Clustering for Time Series Forecasting
Introduction
Time Series Forecasting has been a critical research direction across diverse domains, including traffic, energy, weather, finance, etc. Two channel strategies have been explored in multivariate time series modeling: Channel-Independent (CI) and Channel-Dependent (CD) strategies.
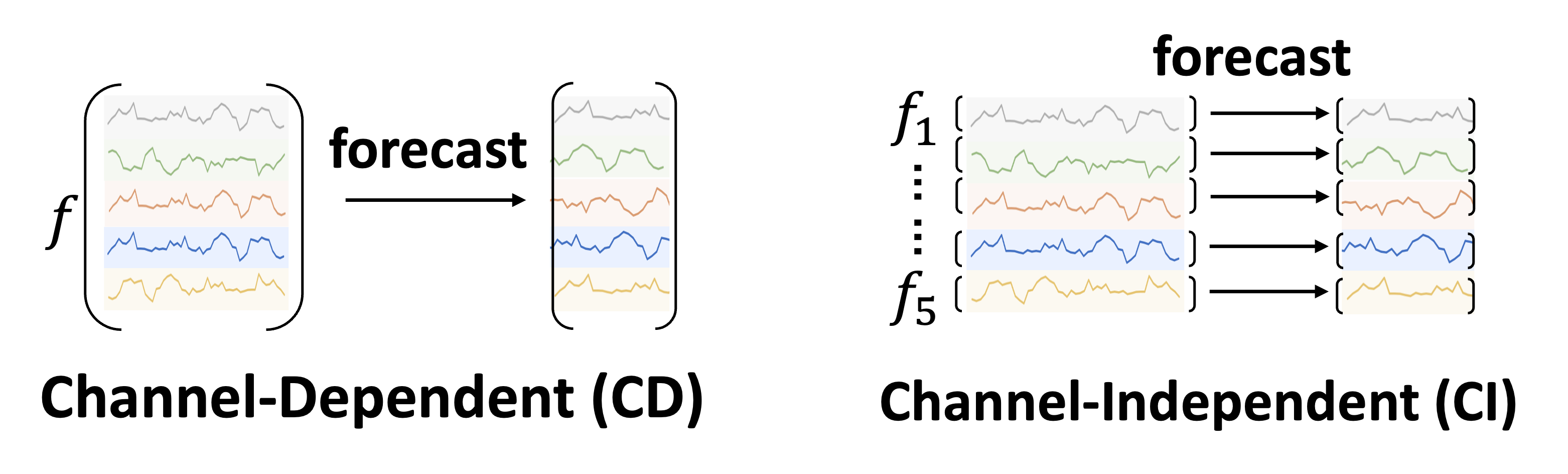 Figure 1: CD and CI comparison
Figure 1: CD and CI comparison
CD models process all channels together, offering better generalization by capturing cross-channel dependencies. However, they suffer from lower accuracy when channels vary in granularity, scale, or frequency, and can mix irrelevant information from different channels. On the other hand, CI models handle each channel separately, leading to better forecasting performance. Yet, they face challenges like limited generalizability to unseen channels, ignoring cross-channel interactions, and higher parameter complexity. This raises a critical research question: How can we develop a channel strategy that effectively balances between individual channel treatment and cross-channel interactions?
Method
Motivation for Channel Similarity
In a toy experiment, we train a time series forecasting model on randomly shuffled channels and compare with the one trained on normal dataset. Channel Shuffling removes the channel identity information. Let and indicate the MSE loss on the -th channel of the model trained on the original dataset and shuffled dataset, respectively. indicates average performance gain across all channels. We define the similarity between the -th and the -th channel based on radial basis function kernels: We investigate Pearson Correlation Coefficients (PCC) between and , indicating the correlation between model’s performance and channel similarity, as shown in the following.
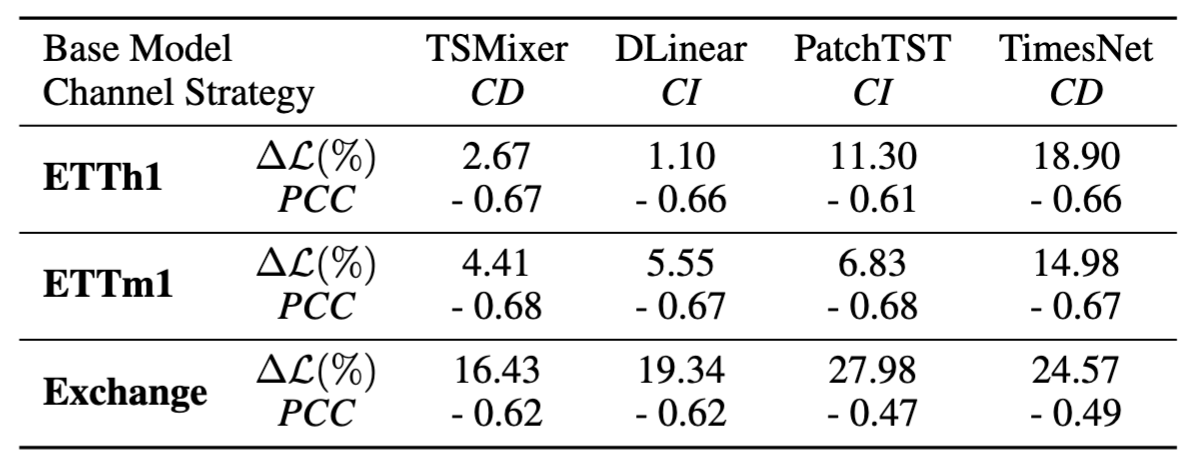 Table 1: Averaged performance gain from channel identity information and Pearson Correlation Coefficients. The values are averaged across all test samples.
Table 1: Averaged performance gain from channel identity information and Pearson Correlation Coefficients. The values are averaged across all test samples.
We empirically observe:
- Existing forecasting methods consistently rely on channel identity information, as is always positive.
- This reliance clearly anti-correlates with channel similarity: for channels with high similarity, channel identity information is less important.
We therefore propose to create clusters based on channel intrinsic similarity and provide the model with cluster identity instead of channel identity. In this way, we combine the best of both worlds: expressiveness and generalization.
CCM Architecture
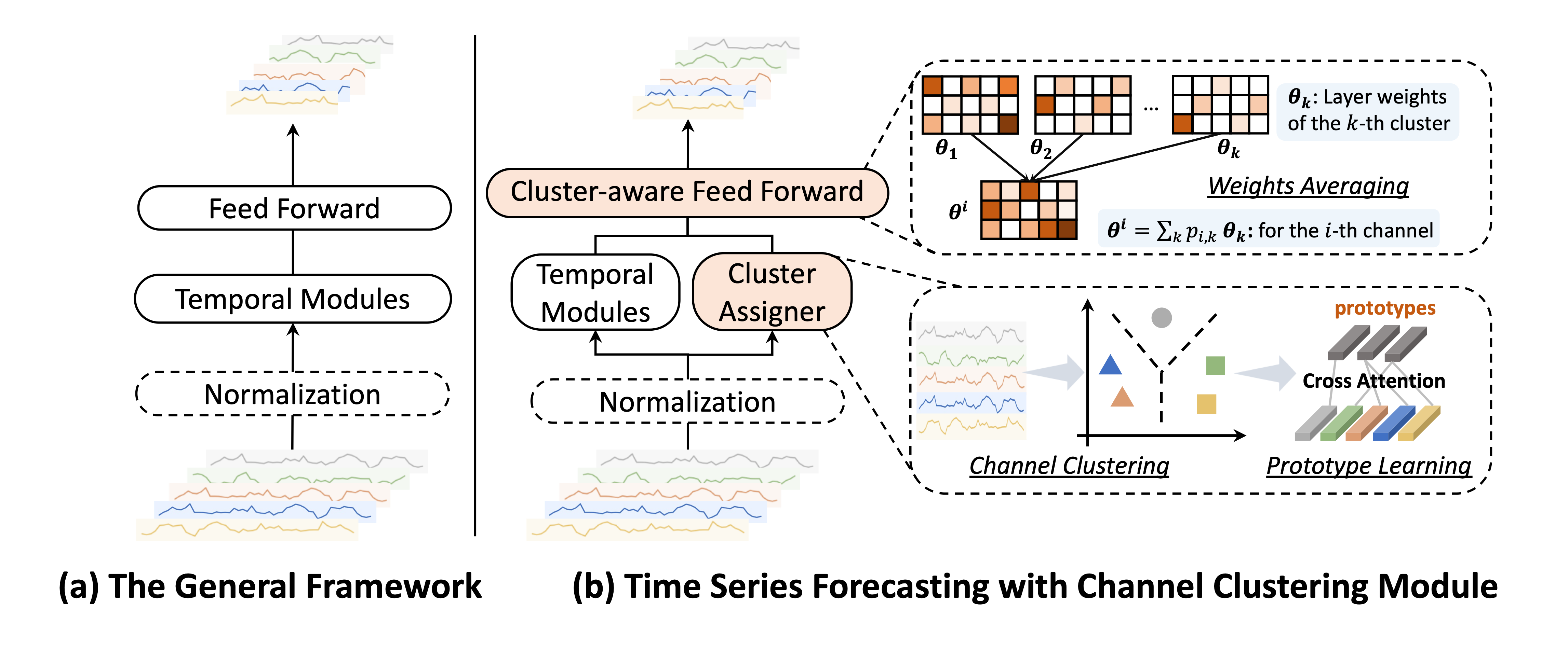 Figure 2: The pipeline of applying Channel Clustering Module (CCM) to general time series models.
We propose Channel Clustering Module (CCM), which explores the optimal trade-off between channel individual treatment and cross-channel modeling.
CCM is a plug-and-play, model-agnostic method that is adaptable to most mainstream models.
Figure 2: The pipeline of applying Channel Clustering Module (CCM) to general time series models.
We propose Channel Clustering Module (CCM), which explores the optimal trade-off between channel individual treatment and cross-channel modeling.
CCM is a plug-and-play, model-agnostic method that is adaptable to most mainstream models.
In Cluster Assigner, each channel () is assigned to a cluster (). The probability that a given channel is associated with the -th cluster is computed as , where is the embedding of cluster and is the embedding of channel . We then sample the clustering membership matrix where . Higher probability results in close to 1, leading to the deterministic existence of certain channels in the corresponding cluster.
In Cluster-aware Feed Forward, we assign a separate Feed Forward layer to each cluster. Let indicate the layer weights for the -th cluster. The weights for the -th channel is , which utilizes the underlying shared time series patterns within the cluster to replace channel identity.
Let indicate embeddings of clusters and channels. In Prototype Learning, is updated by cross-attention during the training phase for subsequent clustering probability computing:
We propose a new cluster loss: , which maximizes the channel similarities within clusters and encourages separation between clusters. This cluster loss captures meaningful time series prototypes without relying on external labels or annotations. The overall loss function thereby becomes , where is the general forecasting loss such as MSE loss; and is a regularization parameter for a balance between forecasting accuracy and cluster quality.
Zero-shot Generalization
Zero-shot forecasting is useful in time series applications where data privacy concerns restrict the feasibility of training models from scratch for unseen samples. The prototype embeddings acquired during the training phase serve as a compact representation of the pre-trained knowledge, which can be harnessed for seamless knowledge transfer to unseen samples in a zero-shot setting. One can use the cluster embedding to calculate the probability of an unseen channel being classified to a certain cluster.
Experiments
We test CCM based on four SOTA time series models:
- TSMixer: MLP-based model (CD)
- Dlinear: single linear layer (CI)
- PatchTST: transformer model with a patch mechanism (CI)
- TimesNet: convolutional network (CD)
Long-term and Short-term Forecasting
We test the CCM's ability of improving time series models' long-term and short-term forecasting accuracy. The datasets involve 9 long-term forecasting datasets from finance, weather, electricity, etc., and M4 dataset for short-term forecasting scenario. We also curate a new stock dataset, including 1390 univariate time series from different companies spanning 10 years.
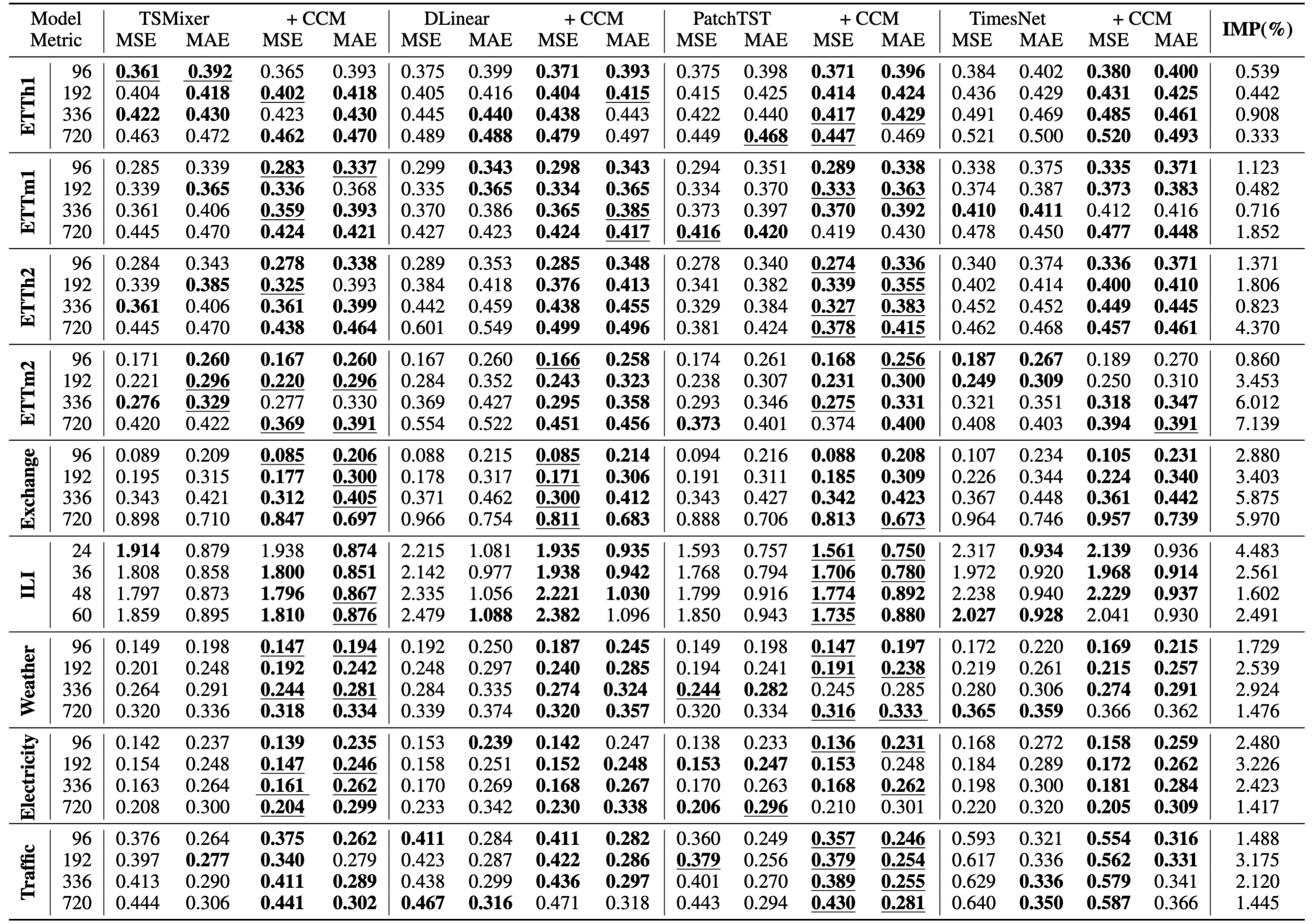 Table 2: Long-term forecasting results on 9 real-world datasets in terms of MSE and MAE, the lower the better. The forecasting horizons are \{96, 192, 336, 720\}. The better performance in each setting is shown in bold. The best results for each row are underlined. The last column shows the average percentage of MSE/MAE improvement of CCM over four base models.
From the table, we observe that the model enhanced with CCM outperforms the base model in general. Specifically, CCM improves long-term forecasting performance in cases in MSE and cases in MAE across 144 different experiment settings.
Table 2: Long-term forecasting results on 9 real-world datasets in terms of MSE and MAE, the lower the better. The forecasting horizons are \{96, 192, 336, 720\}. The better performance in each setting is shown in bold. The best results for each row are underlined. The last column shows the average percentage of MSE/MAE improvement of CCM over four base models.
From the table, we observe that the model enhanced with CCM outperforms the base model in general. Specifically, CCM improves long-term forecasting performance in cases in MSE and cases in MAE across 144 different experiment settings.
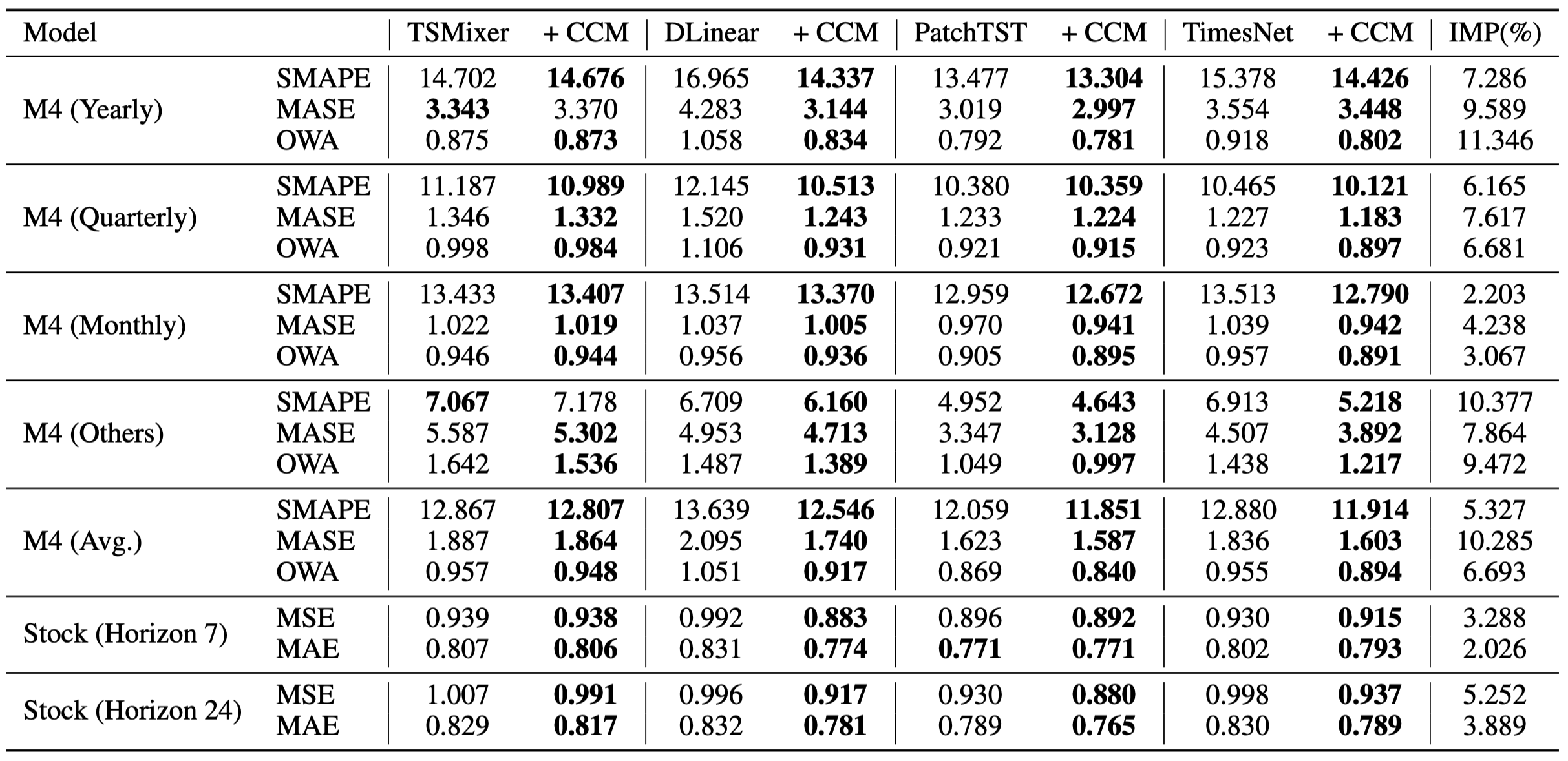 Table 4: Short-term forecasting results on M4 dataset in terms of SMAPE, MASE, and OWA, and stock dataset in terms of MSE and MAE. The lower the better. The forecasting horizon is \{7, 24\} for the stock dataset. The better performance in each setting is shown in bold.
The efficacy of CCM is consistent across all M4 sub-datasets with different sampling frequencies. Specifically, CCM outperforms the state-of-the-art linear model (DLinear) by a significant margin of , and outperforms the best convolutional method TimesNet by . We also observe a significant performance improvement on the stock dataset, achieved by applying CCM.
Table 4: Short-term forecasting results on M4 dataset in terms of SMAPE, MASE, and OWA, and stock dataset in terms of MSE and MAE. The lower the better. The forecasting horizon is \{7, 24\} for the stock dataset. The better performance in each setting is shown in bold.
The efficacy of CCM is consistent across all M4 sub-datasets with different sampling frequencies. Specifically, CCM outperforms the state-of-the-art linear model (DLinear) by a significant margin of , and outperforms the best convolutional method TimesNet by . We also observe a significant performance improvement on the stock dataset, achieved by applying CCM.
Zero-shot to Unseen Time Series
We test the CCM's ability in zero-shot scenarios on ETT dataset collection. ETTh1 and ETTh2 are hourly recorded, while ETTm1 and ETTm2 are minutely recorded, where “1” and “2” indicate two different regions. As shown in Table 5, there are cross-domain and cross-granularity challenges within ETT datasets:
- ①④ require cross-domain generalization
- ②⑤ require cross-granularity generalization
- ③⑥ require cross-domain + cross-granularity generalization
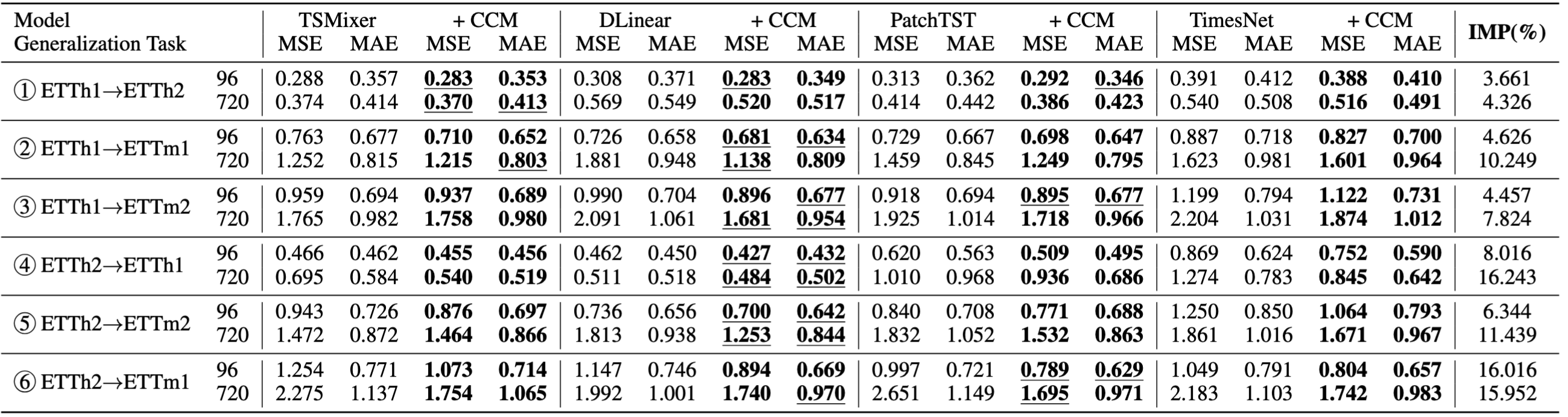 Table 5: Zero-shot forecasting results on ETT datasets. The forecasting horizon is \{96, 720\}
Table 5: Zero-shot forecasting results on ETT datasets. The forecasting horizon is \{96, 720\}
We make the following observations.
- CCM exhibits more significant performance improvement with longer forecasting horizons, highlighting the efficacy of memorizing and leveraging pre-trained knowledge in zero-shot forecasting scenarios
- CCM demonstrates a better effect on originally CI base models.
Cluster Visualization
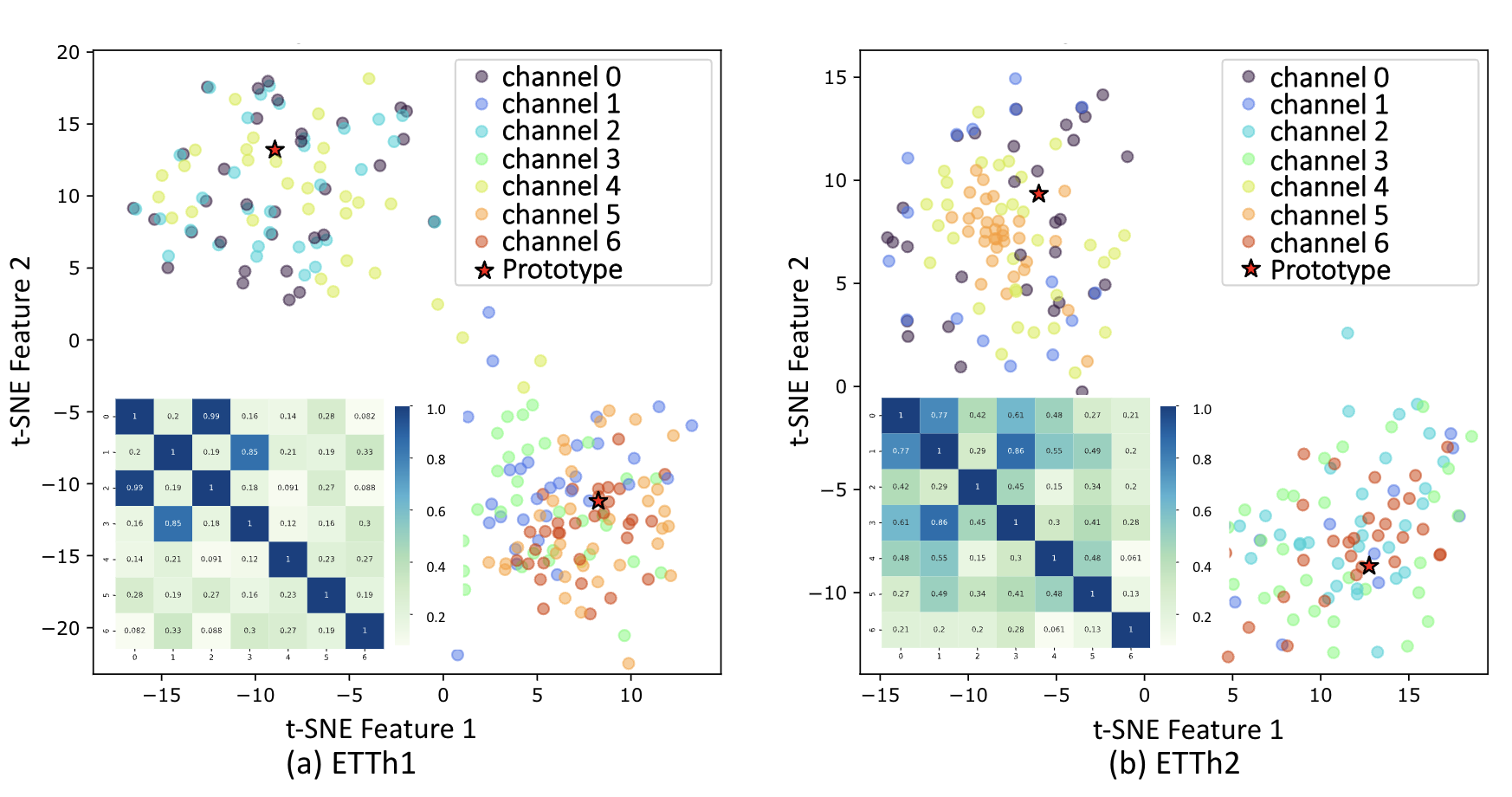 Figure 3: t-SNE visualization of channel and prototype embedding by DLinear with CCM on (a) ETTh1 and (b) ETTh2 dataset. The lower left corner shows the similarity matrix between channels.
As shown in Figure 3, in ETTh1 dataset, we discern a pronounced clustering of channels 0, 2, and 4, suggesting that they may be capturing related or redundant information within the dataset. Concurrently, channels 1, 3, 5, and 6 coalesce into another cluster. Clustering is also observable in ETTh2 dataset, particularly among channels 0, 4, and 5, as well as channels 2, 3, and 6. Comparatively, channel 1 shows a dispersion among clusters, partly due to its capturing of unique or diverse aspects of the data that do not closely align with the features represented by any clusters.
Figure 3: t-SNE visualization of channel and prototype embedding by DLinear with CCM on (a) ETTh1 and (b) ETTh2 dataset. The lower left corner shows the similarity matrix between channels.
As shown in Figure 3, in ETTh1 dataset, we discern a pronounced clustering of channels 0, 2, and 4, suggesting that they may be capturing related or redundant information within the dataset. Concurrently, channels 1, 3, 5, and 6 coalesce into another cluster. Clustering is also observable in ETTh2 dataset, particularly among channels 0, 4, and 5, as well as channels 2, 3, and 6. Comparatively, channel 1 shows a dispersion among clusters, partly due to its capturing of unique or diverse aspects of the data that do not closely align with the features represented by any clusters.